

Iteratoren – Die flexibelen Arrays
Ein Iterator ist eine Schnittstelle, um Daten z.B. über eine foreach-Schleife zu durchlaufen. Gerade bei großen Datenmengen leisten sie eine gute Arbeit, da sich damit das Auslesen der Daten sehr flexibel gestalten kann.
Oftmals werden alle Daten eines SQL-Queries direkt in ein Array zurückgeliefert und dann verarbeitet. Mit Iteratoren ist es auch möglich Daten immer nur schrittweise auszulesen. Das hat den Vorteil, dass die Datenbank punktuell nicht so stark belastet wird.
Iteratoren in PHP
Iteratoren sind jeweils eigene Klassen. Intern arbeiten diese in der Regel mit einem Cursor, also quasi einer Markierung, mit der wir uns merken, welches Element gerade aktuell ist. In PHP muss zum nutzen der Iteratoren das Iterator-Interface implementiert werden. Dies fordert folgende Funktionen:
- current: Liefert das aktuelle Element zurück
- key: Der Schlüssel, zum wiederfinden des aktuellen Elements. Das ist oft eine ID.
- next: Sagt dem Iterator, dass zum nächsten Element gesprungen werden soll
- rewind: Sagt dem Iterator, dass alles zum Anfang gesetzt werden soll (z.B. durch ein Reset des Cursors)
- valid: Gibt zurück, ob das aktuelle Element noch gültig ist. Liefert es false zurück, wird die foreach-Schleife später beendet.
Eine sehr simple Form eines Iterators könnte so aussehen:
<?php class SimpleIterator implements Iterator { private $items = null; private $index = 0; public function current() { return $this->items[$this->index]; } public function key() { return $this->index; } public function next() { $this->index++; } public function rewind() { $this->index = 0; $this->items = array("null", "eins", "zwei", "drei", "vier"); } public function valid() { return count($this->items) > $this->index; } } ?>
Und so benutzt man ihn:
<?php $iterator = new SimpleIterator(); foreach($iterator as $key => $value) { echo $key.":".$value."<br />"; } ?>
Zum Start der Foreach-Schleife wird die rewind-Funktion aufgerufen. Hier wird der Cursor (hier $index) zum Anfang gesetzt und die Daten ausgelesen. Danach wird mit valid geprüft, ob der Eintrag auch wirklich noch gültig ist. Ist das der Fall werden die Werte aus current() und key() der foreach-Schleife übergeben. Am Ende des Foreach-Blocks wird dann mittels next zum nächste Element gesprungen, was dann so lange geht, bis valid false liefert:
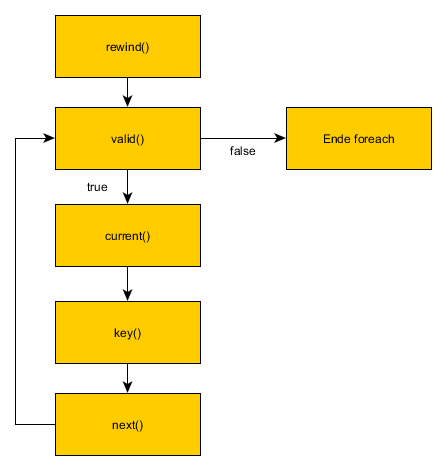
Ablauf beim Durchlaufen eines Iterators
Iterator zum Nachladen
Der wirkliche Vorteil von Iteratoren ist das Nachladen der Daten. Wenn wir eine riesige Datenmenge aus der Datenbank durchlaufen möchte, kann es schon mal Probleme mit dem Speicherverbrauch geben. Innerhalb des Iterators kann man das aber so regeln, dass z.B. immer 100 Einträge gerade im Speicher vorhanden sind. Sind diese 100 durchlaufen, werden sie durch die nächsten 100 ersetzt. Das könnte ungefähr so aussehen:
<?php class DynamicIterator implements Iterator { private $items = null; private $index = 0; private $chunk_size = 2; public function current() { return $this->items[$this->index]; } public function key() { return $this->index; } public function next() { $this->index++; } private function data() { return array("null", "eins", "zwei", "drei", "view", "fünf", "sechs", "sieben", "acht", "neun", "zehn", "elf", "zwölf", "dreizehn", "vierzehn", "fünfzehn"); } private function fetch_data($offset, $limit) { $res = array(); $data = $this->data(); if(count($data) > $offset) { $res = array_slice($data, $offset, $limit); } return $res; } public function rewind() { $this->index = 0; } public function valid() { if(count($this->items) <= $this->index) { foreach($this->fetch_data($this->index, $this->chunk_size) as $item) { $this->items[] = $item; } } return count($this->items) > $this->index; } }
Das rewind ist hier im Gegensatz zum ersten Beispiel recht schlank geworden. Dass hat den Grund, dass wir nicht alle Daten beim Start laden, sondern erst, wenn unser aktueller Satz an Daten abgearbeitet ist.
Stellt die valid-Funktion fest, dass keine Daten mehr vorhanden sind, werden über fetch_data neue Datensätze angefordert. Für ein anschauliches Beispiel gehe ich hier einfach ein festes Array durch. Im realen Einsatz steht in der Funktion aber in der Regel ein Select inkl. Offset und Limit.
Für die geringe Anzahl an Datensätzen habe ich in der $chunk_size-Variable festgelegt, dass pro fetch_data 2 Datensätze geholt werden. In Live-System nutze ich aber eher 1.000- 10.000 Datensätze pro Durchlauf – Oder:
Einen Iterator mit dynamischen Nachladen
Wir wollten ja ursprünglich die Datenbank schonen. Durch die erste Aufteilung haben wir dies schon ein wenig getan, weil während der Abarbeitung des PHPs die Datenbank kurz frei ist, um andere Aufgaben zu erfüllen.
Aktuell nehmen wir aber noch keine Rücksicht darauf, wie sehr die Datenbank aktuell sonst noch ausgelastet ist. Das kann man Ändern, in dem man statt einer festen Anzahl an Elementen eine Zeit angibt, in dem der Select stattfinden soll. Der Iterator passt sich dann nach und nach an der Auslastung der Datenbank an, so dass man am Ende so viele Elemente holt, dass es von der Zeit her relativ passend ist.
Auf unser Beispiel angewendet sieht das so aus:
<?php class DynamicIterator implements Iterator { private $items = null; private $index = 0; private $chunk_size = 2; private $destination_time = 5; public function current() { return $this->items[$this->index]; } public function key() { return $this->index; } public function next() { $this->index++; } private function data() { return array("null", "eins", "zwei", "drei", "view", "fünf", "sechs", "sieben", "acht", "neun", "zehn", "elf", "zwölf", "dreizehn", "vierzehn", "fünfzehn"); } private function fetch_data($offset, $limit) { $res = array(); $data = $this->data(); if(count($data) > $offset) { $res = array_slice($data, $offset, $limit); } sleep($limit); return $res; } public function rewind() { $this->index = 0; } public function valid() { if(count($this->items) <= $this->index) { $start = time(); foreach($this->fetch_data($this->index, $this->chunk_size) as $item) { $this->items[] = $item; } $runtime = time()-$start; //Hat zu lange gebraucht, beim nächsten Mal etwas langsamer. if($runtime > $this->destination_time & $this->chunk_size > 0) { $this->chunk_size--; } //Noch unter der Zeit, Tempo erhöhen! else if($runtime < $this->destination_time) { $this->chunk_size++; } echo "Chunk-Size:".($this->chunk_size)."<br />"; } return count($this->items) > $this->index; } } $iterator = new DynamicIterator(); foreach($iterator as $key => $value) { echo $key.":".$value."<br />"; } ?>
Ich habe für jeden Datensatz mal ein Sleep von einer Sekunde eingebaut. Die Zielzeit ($destination_time) ist eine Sekunde, somit sollte der Iterator pro Durchlauf 5 Datensätze aus der Datenbank holen. Im valid wird dann die Zeit gemessen und verglichen. Ging es zu schnell, können beim nächsten Mal mehr Datensätze geholt werden => Chunk-Size um einen vergrößern. War es zu langsam, dürften wir beim nächsten Mal nicht mehr ganz so viel holen. Die Größe muss aber immer über Null bleiben, weil der Iterator ja sonst zum Stillstand kommt.
Im produktiven Einsatz würde ich statt einen hinzuzufügen oder abzuziehen mit Prozenten arbeiten. Das heißt, dass der Anteil, der bei der Zeit fehlte auf die Chunk-Größe addiert wird. So kommt man dem Ziel noch schneller Nahe. Das ist bei kleineren Datenmengen aber etwas schwieriger, da man ja immer auf volle Zahlen springen muss und die Zeiten somit nicht so leicht steuern kann.
Fazit: Auf jedem Fall zu empfehlen
Ich habe beruflich häufig mit großen Datenmengen zu tun und habe deswegen die Iteratoren sehr zu schätzen gelernt. Was ich hier gezeigt habe ist ja nur die Basis. Iteressanter wird es, wenn man in die Iteratoren zum Beispiel noch Filter einbauen, um die Datensätze zu filtern.
Du arbeitest in einer Agentur oder als Freelancer?
Dann wirf doch mal einen Blick auf unsere Software FeatValue.
Weiterlesen: ⯈ Error Handling und Debugging
Über uns

Wir entwickeln Webanwendungen mit viel Leidenschaft. Unser Wissen geben wir dabei gerne weiter. Mehr über a coding project