

Arbeiten mit Datenbank Indizes
Ein häufiger Grund für langsame Ladezeiten sind Datenbankabfragen. Geht eine Website gerade an den Start sind die Datenbanken in der Regel noch nicht so stark befüllt. Nach und nach kommen neue Einträge in die Datenbank und die Datenbankabfragen werden langsamer. Schließlich müssen jetzt bei SELECTs auch mehr Datensätze durchsucht werden.
Dieses Heraussuchen der Datensätze kann man über so genannte Indizes (singular Index) beschleunigen. Damit wird nicht mehr jeder Datensatz durchlaufen und geprüft, was dann einiges an Ladezeit spart.
Wie eine Datenbankabfrage ohne Index funktioniert:
Gehen wir einmal davon aus, dass wir folgende Tabelle haben (kein Index hinterlegt):
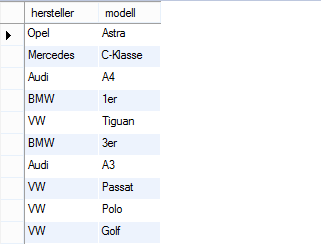
Tabelle ohne Index
Wenn wir uns jetzt Alle Modelle von BMW herraussuchen wollen, können wir dies mit folgendem SELECT machen:
SELECT * FROM autos WHERE hersteller = 'BMW';
Im Hintergrund geht die Datenbank nun her und führt folgende Vergleiche aus:
- „Opel“ (Astra)= „BMW“?
- „Mercedes“ (C-Klasse) = „BMW“?
- „Audi“ (A 4)= „BMW“?
- „BMW“ (1er) = „BMW“?
- „VW“ (Tiguan) = „BMW“?
- „BMW“ (3er) = „BMW“?
- „Audi“ (A3) = „BMW“?
- „VW“ (Passat) = „BMW“?
- „VW“ (Polo) = „BMW“?
- „VW“ (Gold)= „BMW“?
Er ging jetzt jeden Datensatz durch und musste somit 10 Hersteller vergleichen. Das bekommen wir schneller hin!
Primary Key: Ein besonderer Index
Es gibt mehrere Arten von Indizes. Der bekannteste dürfte wohl der Primary Key sein. Dieser legt für eine Tabelle fest, an Hand welchen Kriterien ein einzelner Datensatz wiedererkannt werden kann. Häufig wird hier eine ID genommen, aber auch ein Primary Key über eine Varchar-Spalte oder gar mehrere Spalten ist möglich. In unserem Fall würde ein Primary Key auf beide Spalten Sinn machen. Das geht dann zum Beispiel so:
ALTER TABLE`autos` CHANGE COLUMN `hersteller` `hersteller` VARCHAR(255) NOT NULL , CHANGE COLUMN `modell` `modell` VARCHAR(255) NOT NULL , ADD PRIMARY KEY (`hersteller`, `modell`) ;
Neben dem ADD PRIMARY KEY wurden die Spalten auch auf NOT NULL gesetzt, weil NULL-Werte in einem Primary Key nicht erlaubt sind.
Wenn man jetzt einen SELECT auf die Tabelle ausführt, sieht man, dass sich die Sortierung verändert hat:
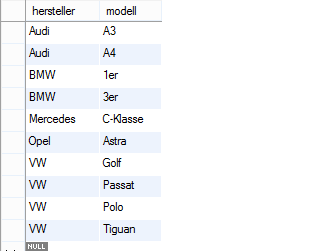
Tabelle mit Primary Key
Nun wird erst an Hand des Herstellers und wenn die gleich sind an Hand des Modells sortiert. Würde man die Spalten in unserem ADD PRIMARY KEY andersherum auflistet, wäre auch die Sortierung anderherum.
Wenn wir jetzt unseren SELECT ausführen, sehen die Vergleiche in etwa so aus:
- „Mercedes“ (C-Klasse) = „BMW“?
- „Audi“ (A4) = „BMW“?
- „BMW“ (1er) = „BMW“?
- „BMW“ (3er) = „BMW“?
Im Prinzip geht die Datenbank jetzt her und holt sich den Datensatz aus der Mitte (Datensatz 5) und schaut, ob dieser übereinstimmt. In diesem Fall ist die Mercedes C-Klasse. Ist kein BMW. Da Mercedes im Alphabet hinter BMW steht, muss BMW also weiter vorne liegen. Also nimmt er jetzt die Mitte der vier Datensätze davor, was dann der Zweite (Audi A4) Wäre. Ist aber auch kein BMW. Das heißt die Datensätze müssen zwischen dem Audi und Mercedes liegen. Also geht er wieder in der Mitte. Das ist diesmal nur ein Datensatz weiter und da hat er den ersten Datensatz gefunden. Jetzt geht er die nächsten Datensätze so lange durch, bis er keinen BMW mehr findet. Im Anschluss würde er dann rückwärts gehen, aber da er den Audi bereits geprüft hat, braucht er das nicht mehr machen.
Würde man jetzt Hersteller und Modell angeben, müsste er das nach oben und unten suchen auch nicht mehr ausführen, so wäre die Abfrage noch einmal schneller.
Dabei herum kommt, dass wir uns durch den Primary Key nun 6 Vergleiche gespart haben. Das würde in der Theorie bedeuten, dass die Abfrage nun doppelt so schnell läuft. Bei 10 Datensätzen ist das nicht wirklich spürbar. Nehmen wir aber mal an, es wären 10.000. Dabei kann die Ladezeit je nach Abfrage sogar um ein Vielfaches schneller sein.
Einen Index anlegen
Jetzt kann man aber auch normale Indizes anlegen, ohne die spezielle PRIMARY-KEY-Funktion. Das bedeutet, dass die genommenen Spalten nicht eindeutig sein müssen. Legen wir einen solchen Index doch einmal über die Spalte „modell“ an:
ALTER TABLE `demo`.`autos` INDEX ADD `ix_modell` (`modell` ASC) ;
Da es auf eine Tabelle mehrere Indizes geben kann, sollte hier auch ein Namen angegeben werden. Ich schreibe vor meine Indizes in der Regel ein „ix_“ und dann den Namen der Spalte bzw. einen Begriff, der die ausgewählten Spalten beschreibt. Vielleicht fällt euch hier das Wort „ASC“ auf. Das kennt ihr bestimmt schon vom ORDER BY Befehl. Wie oben beschrieben, funktionieren Indizes ja über Sortierung. Mit dem ASC bzw. DESC kann man also auch hier festlegen, wie die Tabelle intern sortiert werden sollte.
Durch das Erstellen des Indexes wird im Hintergrund eine Art Zuordnungs-Tabelle erstellt. In unserem Fall könnte diese so aussehen:
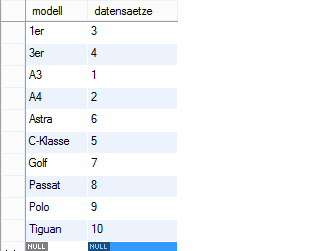
Aufbau eines Index
(Bitte beachten, dass dieser Aufbau nur zur Erklärung dient. Der wirkliche interne Aufbau kann durchaus anders sein)
In dieser Art Tabelle wurden jetzt die Modelle sortiert und dessen Eintrags-Positionen in der Haupttabelle notiert. Da ein Index nicht eindeutig ist, können hier auch mehrere Positionen zu einem Modell stehen.
Erkennt die Datenbank jetzt, dass du in deiner WHERE Bedingung nur auf die Spalte modell gehst, wird er das Herraussuchen der Datensätze über diese Tabelle erledigen. Es wird also vor jedem Herraussuchen von der Datenbank abgewogen, welcher Index nun am besten passt und somit am schnellsten ausgeführt wird.
Allerdings wird durch einen Index das Einfügen in die Datenbank leicht langsamer. Schließlich muss ja jetzt zusätzlich ein neuer Eintrag in die Zuordnungs-Tabelle gemacht werden. Aus diesem Grund sollte man im ideallfall auch nur Indizes anlegen, wo man sie wirklich gebraucht.
UNIQUE Indizes
Neben dem normalen Index gibt es auch noch weitere Arten von Indizes. Eine, die ihr für den Anfang vielleicht noch wissen solltet, ist der UNIQUE-Index. Dieser beinhaltet, wie auch der Primary Key, nur eindeutige Datensätze. Kann aber im Gegensatz zum Primary Key auch mehrfach angelegt werden. Er sollte aber nicht als Ersatz für den Primary Key gesehen werden, sondern nur als Zusatz. Wichtig: Der UNIQUE Index ignoriert NULL-Werte. Das heißt, ein NULL Wert kann mehr als nur einmal darin vorkommen.
Datenbankabfragen auf einen Index optimieren
Beim Optimieren der Datenbankabfragen muss nicht immer immer ein neuer Index her. Man kann die WHERE-Bedingungen auch so erweitern, dass ein bereits bestehender Index genutzt werden kann. Wenn ihr in unserem Beispiel nach dem Modell „A4“ sucht und schon wisst, dass es diesen nur bei Audi gibt, könnt ihr „Audi“ einfach mit in dem Select aufnehmen und könnt damit über den Primary Key gehen. Ein Index wäre nicht mehr nötig.
Herausfinden, welcher INDEX genutzt wird
Im Ideallfall solltet ihr vor der Optimierung einer langsamen Abfrage einmal schauen, wo das Problem genau liegt. Gerade wenn über mehrere Tabellen gejoint wird, ist es manchmal nicht auf dem ersten Blick ersichtlich, wo ein Index fehlt. In MySQL geht dies über Explain:
EXPLAIN SELECT * FROM demo.autos where modell = 'A4';
Im Ergebnis seht ihr in der Spalte „key“ welcher Index aktuell genutzt werden würde. Die Zahl, die in der Spalte „rows“ steht sollte nach Möglichkeit gering sein. Das ist die Anzahl der Zeilen, die zum Beispiel bei einem JOIN selektiert wird. Die Spalte „Extra“ sagt, wie die Datensätze herausgesucht werden. Im Ideallfall sollte hier „Using index“ auftauchen. Steht dort „Filesort“ sollte hier auf jedem Fall optimiert werden, weil hier jeder Datensatz überprüft wird.
Fazit
Indizes gehören in jedem größeren Programmierungs-Projekt einfach mit dazu. Durch sie kann eine Datenbankabfrage die vorher einige Minuten gedauert hat plötzlich unter einer Sekunde ausgeführt werden. Man sollte sie allerdings nur gezielt einsetzen, weil mit ihnen auch der Speicherverbrauch und die Ladezeit beim Einfügen und Ändern von Datensätzen leicht steigen.
Verwandte Artikel
Du arbeitest in einer Agentur oder als Freelancer?
Dann wirf doch mal einen Blick auf unsere Software FeatValue.
Kommentare
Neeldarax schrieb am 07.08.2013:
Hi, bei "Wenn wir uns jetzt Alle Modelle von Audi herraussuchen wollen, können wir dies mit folgendem SELECT machen: SELECT * FROM autos WHERE hersteller = 'BMW';" musst dich ma für Audi oder BMW entscheiden :) Ansonsten find ich den Beitrag hilfreich!
Stefan Wienströer schrieb am 07.08.2013:
Lol hatte mich erwischt^^ Ich hatte erst Audi gewählt, dann ist mir aber aufgefallen, dass das ja ganz am Anfang liegt und somit eher schlecht zum Erklären des Herraussuchens geeignet ist^^
Timo schrieb am 07.08.2013:
Das ist auf jedenfall ordentlich hilfreich, wenn die Suche nur noch logarithmisch statt linear abläuft. Hab da bei einem Projekt auch schon viel rumprobiert, sollte man auf jedenfall in die Überlegungen zur Datenbank immer mit einbeziehen.
Umgang mit IP-Adressen in MySQL schrieb am 12.08.2013:
[…] die IP noch als String speichert nach Möglichkeit vermeiden. Denn so geht ihr nicht über einen Index, was die ganze Abfrage […]
Über uns

Wir entwickeln Webanwendungen mit viel Leidenschaft. Unser Wissen geben wir dabei gerne weiter. Mehr über a coding project