

MySQL: Datenbankmodelierung
MySQL ist ein Datenbank-Management-System (DBMS). Man kann es sich - ebenso wie andere DBMS - als eine Sammlung von Tabellen vorstellen, die untereinander in Beziehungen stehen. Dazu kommen dann noch Werkzeuge und Hilfsdaten, die wir später beschreiben. Tabellen sind den meisten Computerbenutzern von Excel bekannt. Tabellen haben Spalten und Zeilen - in MySQL und jeder anderen relationalen Datenbank sind die Tabellen logisch genauso aufgebaut. Eine Tabellenzeile nennt man hier auch Datensatz (weil dort mehrere Daten zu einem Satz Daten zusammengefasst sind), engl. record. Die Spalten heißen Felder, und sie haben Namen, nicht nur A, B, C... wie in Excel, sondern sprechende Namen wie KundenNr oder RechDatum.Ein erstes Beispiel
Versuchen wir es mit einem ersten Anwendungsbeispiel:| Typ | Bezeichnung | Farbe | Hersteller | Einkaufspreis | Verkaufspreis |
|---|---|---|---|---|---|
| Faserstift | Schreibersglück | rot | Stifty | 0,5 | 0,6 |
| Faserstift | Schreibersglück | blau | Stifty | 0,5 | 0,6 |
| Faserstift | Schreibersglück | grün | Stifty | 0,4 | 0,5 |
| Faserstift | Schreibersglück | gelb | Stifty | 0,5 | 0,6 |
| Faserstift | Fasano | blau | Fasanetic | 0,4 | 0,45 |
Das ist der Inhalt eines Befehls. Den müssen wir nun nur noch in die Sprache übersetzen, die MySQL versteht, und schon haben wir unsere erste Bearbeitung in der Datenbank abgeschlossen. Nach diesem Prinzip funktionieren die meisten Zugriffe auf eine Datenbank:
- Nimm eine Tabelle
- Suche bestimmte Datensätze anhand der Werte, die in bestimmten Feldern stehen
- Tu etwas mit den gefundenen Datensätzen: den Inhalt von Feldern anzeigen oder ändern oder die Datensätze löschen.
Beziehungen zwischen Tabellen
Das Besondere an einer Datenbank ist nun, dass die Tabellen untereinander in Beziehungen stehen können. Die Beziehungen lassen sich an folgendem Beispiel verdeutlichen:Ein Schreibwaren-Laden bezieht Schreibwaren von einem Großhändler und verkauft sie an seine Kunden weiter. Um den Überblick zu behalten speichert der Händler seine Waren in einer Datenbank. Die Liste der Waren beginnt mit Faserstiften und könnte etwa so aussehen wie obige.
Man sieht auf den ersten Blick das Problem: Viele Daten wiederholen sich. Die ersten 4 Datensätze sind fast gleich, sie unterscheiden sich nur in der Farbe und in den Preisen. Beim Speichern wird dadurch nicht nur Speicherplatz durch überflüssige Wiederholungen verschwendet, schlimmer noch ist, dass wenn mal ein Eintrag geändert werden muss (z.B. wenn der Hersteller von einer anderen Firma übernommen wurde und sich dadurch der Name ändert), müssen viele gleiche alte Einträge in gleiche neue Einträge geändert werden. Das birgt Risiken. Um das zu vermeiden, schreibt man gleiche Einträge nur einmal und verteilt sie ggf. auf mehrere Tabellen. Das würde in unserem Beispiel so aussehen:
Tabelle "Artikel":
| Typ | Bezeichnung | Hersteller | ArtikelNr |
|---|---|---|---|
| Faserstift | Schreibersglück | Stifty | 1 |
| Faserstift | Schreibersglück | Faserino | 2 |
| Faserstift | Fasano | Fasanetic | 3 |
| ArtikelNR | Farbe | Einkaufspreis | Verkaufspreis |
|---|---|---|---|
| 1 | rot | 0,5 | 0,6 |
| 1 | blau | 0,5 | 0,6 |
| 2 | rot | 0,4 | 0,5 |
| 2 | blau | 0,5 | 0,6 |
| 3 | blau | 0,4 | 0,45 |
Zwischen den Tabellen Artikel und Preis besteht also eine Beziehung, die über die Spalte (das Feld) ArtikelNr hergestellt wird: Zeilen mit der gleichen ArtikelNr in beiden Tabellen gehören zusammen.
Auf diesem Prinzip baut die gesamte Tabellen-Architektur einer Datenbank auf, wenn es hier natürlich auch sehr vereinfacht dargestellt ist. Die Zeile
| Faserstift | Stifty | Faserino | 2 |
Das Entity-Relationship-Modell
Um den Aufbau und Änderungen in Datenbanken überschaubar und verständlich zu machen, wurden wissenschaftliche Modelle entwickelt. Eins davon ist das Entity-Relationship-Modell (ER-Modell). Dabei heißt eine Zeile einer Tabelle "Entity" und Relationship sind die Beziehungen, die zwischen bestimmten Feldern der Tabellen bestehen.Das ER-Modell betrachtet alle gespeicherten Daten als Objekte. Im Modell heißt ein Objekt Entity, wobei jedes Entity wiederum mit bestimmten Eigenschaften gespeichert wird, die man Attribute nennt.
Auf unser vorangegangenes Beispiel übertragen heißt das:
Das Entity Hersteller ist mit den Attributen Name, Anschrift, TelefonNr usw. gespeichert. Das Entity Artikel ist mit den Attributen ArtikelNr, Typ, Bezeichnung, Hersteller gespeichert. Entities, welche die gleichen Attribute haben, werden zu Entity-Typen zusammengefasst.
Um das ER-Modell einer Datenbank grafisch darzustellen, wurden Standards vereinbart, die Notation. In der am weitesten verbreiteten Version der Notation wird ein Entity-Typ als Rechteck dargestellt, seine Attribute als Oval. Attribute sind mit dem Entity-Typ durch Linien verbunden. Unsere Tabelle Preis sieht in der Notation des ER-Modells so aus:
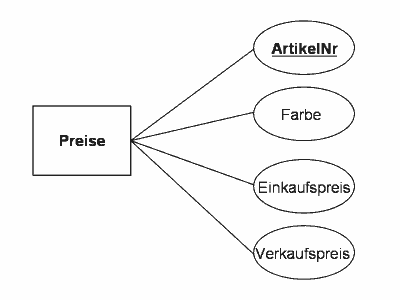
Darstellung: ER-Modell anhand der Preise-Tabelle
Für die Beziehungen zwischen Tabellen in einer Datenbank gibt es strenge Regeln. Sie lassen sich am besten am Beispiel zeigen:
Eine ArtikelNr (z.B. die 2) darf es in der Tabelle Artikel nur einmal geben. Wenn es sie zweimal geben würde, wüsste man ja nicht mehr, ob die ArtikelNr 2 in der Preistabelle sich nun auf die eine oder die andere Bezeichnung bezieht. Die ArtikelNr ist also ein eindeutiger Wert. Man nennt sie den "Schlüssel" (engl. key) in dieser Tabelle, weil sie eine Zeile (einen Datensatz) hier eindeutig identifiziert. Eindeutige Schlüssel (unique key) heißen auch Primärschlüssel (primary key). Sie spielen in Datenbanken eine große Rolle, weil es nur durch sie möglich ist, einen bestimmten Datensatz einer Tabelle eindeutig zu identifizieren. Im ER-Modell wird der Name des Primärschlüssels unterstrichen.
In der Tabelle "Preis" hat die ArtikelNr dagegen eine andere Funktion: sie kann beliebig oft vorkommen, verweist aber auf den Schlüssel in der anderen, fremden Tabelle "Artikel", es handelt sich also um einen "Fremdschlüssel" (engl. foreign key). Ein Schlüssel kann ein einzelnes Feld sein (z.B. die ArtikelNr), er kann sich aber auch über mehrere Felder erstrecken. Zum Beispiel könnte man die Felder Typ, Hersteller und Bezeichnung zu einem Schlüssel zusammenfassen und sie anstelle der ArtikelNr gebrauchen.

Darstellung: Darstellung der Beziehungen zweier Tabellen
Zwischen den Feldern ArtikelNr aus Tabelle Artikel und ArtikelNr aus Tabelle Preis besteht also eine Beziehung: Schlüssel zu Fremdschlüssel. Die Tatsache, dass es eine ArtikelNr in der Tabelle Artikel nur einmal geben darf, in der Tabelle Preis jedoch beliebig oft (n-mal), nennt man eine 1:n-Beziehung. Sie ist die häufigste, daneben gibt es 1:1 und m:n-Beziehungen (letzteres bedeutet: ein Schlüsselwert darf beliebig oft in der einen und beliebig oft in der anderen Tabelle auftreten. m:n-Beziehungen bestehen nur im Modell: In Datenbanken werden sie mit Hilfe einer Zwischentabelle in 2 Beziehungen aufgelöst (m:1+1:n).
Die Visualisierung des ER-Modells ist das Entity-Relationship-Diagramm (ERD). Unser Beispiel lässt sich so darstellen:
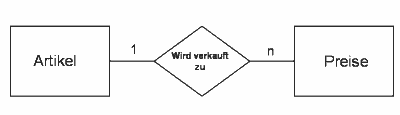
Darstellung: Beziehung der Artikel zu den Preisen
Das relationale Datenmodell
Einfache Beziehungen lassen sich als Hierarchie darstellen:1 Typ
2 Hersteller
3 Artikel
5 Preise
In realen Anwendungen sind die Beziehungen zwischen Tabellenfeldern natürlich weitaus komplizierter. Stellen wir uns als Beispiel die Daten eines Versandhauses vor. Immer noch vereinfacht, könnten die Tabellen so aussehen:
Darstellung: Abbildung vieler Beziehungen von Objekten untereinander
Im relationalen Datenmodell werden die Entity-Typen und Relationship-Typen (die Beziehungen) des ER-Modells "Relationen" genannt und als Tabellen dargestellt. Eine Tabellezeile ist dann ein Datensatz einer Relation, eine Tabellenspalte ist ein Attribut. Und damit sind wir schon fast wieder bei unseren Tabellen von oben.
Warum soviel Theorie?
Alle modernen Datenbanksysteme arbeiten auf der Basis des relationalen Datenbankmodells. Eine Datenbank, die das reale Geschäftsleben darstellen soll, ist nur mit gründlicher Vorüberlegung effektiv aufzubauen und zu pflegen. Zeit und Intelligenz, die hier investiert werden, zahlen sich später aus, denn eine nachträgliche Änderung kann weitaus aufwendiger und nervenaufreibender sein. Man spricht nicht ohne Grund vom "Datenbank-Design".
Welche Tabellen sollen welche Spalten (Felder) und Daten enthalten? Welches sollen die Schlüsselfelder sein? Diesen Prozess bezeichnet man als "Normalisierung". Jede Tabelle wird bei der Normalisierung in eine bestimmte "Normalform" gebracht. Es gibt 9 Stufen der Normalisierung (viele Informationsquellen nennen auch nur 6), die aufeinander aufbauen. In der Praxis betreibt man die Normalisierung im Allgemeinen bis zur 3.Normalform. Die einzelnen Normalformen näher zu erklären, würde in diesem Zusammenhang zu weit führen. Hier beschreiben wir nur kurz die Eigenschaften der 3.Normalform. Eine Tabelle ist in der 3.Normalform, wenn sie folgende Kriterien erfüllt:
1 .Jedes einzelne Feld in allen Datensätzen darf nur jeweils eine Information enthalten (es muss "atomar" sein), also keine Listen
2. Ein Feld oder mehrere Felder gemeinsam müssen den Primärschlüssel dieser Tabelle bilden. Alle Felder, die nicht zum Primärschlüssel gehören, müssen von diesem abhängig sein.
3. Es dürfen keine funktionalen Abhängigkeiten existieren zwischen Attributen, die nicht als Schlüssel definiert sind, d.h. alle Attribute, die nicht zum Primärschlüssel gehören, müssen direkt von diesem abhängig sein.
In unseren Beispielen haben wir die Normalisierung bis zur 3.Normalform praktisch schon durchgeführt.
Du arbeitest in einer Agentur oder als Freelancer?
Dann wirf doch mal einen Blick auf unsere Software FeatValue.
Weiterlesen: ⯈ Werkzeuge für MySQL
Über uns

Wir entwickeln Webanwendungen mit viel Leidenschaft. Unser Wissen geben wir dabei gerne weiter. Mehr über a coding project